Sizzle浅析-5
- Time: 26 November 2012
- Categories:
- Frontend 27
- Tags:
- Sizzle 7
- jQuery 7
- Javascript 21
上篇文章分析了Sizzle的查找功能。较之于查找,过滤就显得颇为复杂了。它分为元素之间的过滤和元素自身过滤(filter)。元素之间的过滤分为:相邻兄弟过滤,父级过滤,祖先过滤,通用兄弟过滤,这四种过滤方式定义在Expr.relative对象中。自身过滤由Sizzle.filter方法完成。
###元素间过滤——Expr.relative
####相邻兄弟过滤——”+” 要过滤相邻兄弟节点,故将映射集中的每个元素的上一个相邻兄弟节点和传入的参数part做比较。将对应的比较结果存入映射集。由于part的类型不确定,所以源码中针对每个类型做了不同的处理,具体看下面代码中的注释。
var Expr.relative['+'] = function (checkSet, part) {
var isPartStr = typeof part === "string",
isTag = isPartStr && !/\W/.test(part),
isPartStrNotTag = isPartStr && !isTag; // 块表达式
if (isTag) {
part = part.toLowerCase();
}
for (var i = 0, l = checkSet.length, elem; i < l; i++) {
if ((elem = checkSet[i])) {
// 查找上一个相邻的Element类型节点(部分浏览会把Element节点直接的换行符也当作一个Text节点)
while ((elem = elem.previousSibling) && elem.nodeType !== 1) {}
//注意逻辑运算符的优先级 "===" > "&&" > "||" > "?"
// 如果part是tag或块表达式,返回elem||false
// 否则(part是Element类型),返回elem===part
checkSet[i] = isPartStrNotTag || elem && elem.nodeName.toLowerCase() === part ? elem || false : elem === part;
}
}
// 如果是块表达式,则调用自身过滤
if (isPartStrNotTag) {
Sizzle.filter(part, checkSet, true);
}
};
####父级元素过滤——”>” 相邻兄弟过滤器类似,取映射集中每个元素的父级节点和part比较,根据part类型的差异,将对应的比较结果存入映射集。
var Expr.relative['>'] = function (checkSet, part) {
var elem, isPartStr = typeof part === "string",
i = 0, l = checkSet.length;
// 如果是tag类型
if (isPartStr && !/\W/.test(part)) {
part = part.toLowerCase();
for (; i < l; i++) {
elem = checkSet[i];
if (elem) {
var parent = elem.parentNode;
checkSet[i] = parent.nodeName.toLowerCase() === part ? parent : false;
}
}
// part为块表达式或Element节点
} else {
for (; i < l; i++) {
elem = checkSet[i];
if (elem) {
checkSet[i] = isPartStr ? elem.parentNode : elem.parentNode === part;
}
}
if (isPartStr) {
Sizzle.filter(part, checkSet, true);
}
}
};
####祖先元素过滤——”” 和 通用兄弟过滤——”~” 祖先元素过滤和通用兄弟过滤都涉及递归查询操作(祖先元素过滤需要递归查找父级元素,通用兄弟过滤需要递归查找上一个相邻节点),所以我合在一起说明。
var Expr.relative[''] = function (checkSet, part, isXML) {
var nodeCheck, doneName = done++,
checkFn = dirCheck;
if (typeof part === "string" && !/\W/.test(part)) {
part = part.toLowerCase();
nodeCheck = part;
checkFn = dirNodeCheck;
}
checkFn("parentNode", part, doneName, checkSet, nodeCheck, isXML);
// 通用兄弟过滤这里传递的的参数是 previousSibling
// checkFn("previousSibling", part, doneName, checkSet, nodeCheck, isXML);
};
在这里只做简单的入口判断,核心过滤工作是交给dirNodeCheck或dirCheck来实现(如果part是tag类型则交给dirNodeCheck处理,否则交给dirCheck处理)。
递归查询候选集中每个元素的相对元素(父级元素或上一个兄弟节点),直到发现该相对元素的nodeName恰好等于传入的tagName(cur)。这里使用了缓层技术减少循环判断次数,极大提升了过滤效率。
function dirNodeCheck(dir, cur, doneName, checkSet, nodeCheck, isXML) {
for (var i = 0, l = checkSet.length; i < l; i++) {
var elem = checkSet[i];
if (elem) {
var match = false;
elem = elem[dir];
while (elem) {
if (elem.sizcache === doneName) {
match = checkSet[elem.sizset];
break;
}
if (elem.nodeType === 1 && !isXML) {
elem.sizcache = doneName;
elem.sizset = i;
}
if (elem.nodeName.toLowerCase() === cur) {
match = elem;
break;
}
elem = elem[dir];
}
checkSet[i] = match;
}
}
}
处理完元素之间的过滤,再看看元素自身的过滤。
###元素自身过滤——Expr.filter
如同Sizzle.find,Sizzle.filter也只是过滤方法的一个入口。首先根据正则来判断选择器的类型,然后调用对应的预过滤函数(Expr.preFilter)和过滤函数(Expr.filter)处理。
// 特殊参数说明
// inplace 是否在原结果中修改
// not 是否取补集
Sizzle.filter = function (expr, set, inplace, not) {
var match, anyFound, old = expr,
result = [],
curLoop = set,
isXMLFilter = set && set[0] && Sizzle.isXML(set[0]);
while (expr && set.length) {
for (var type in Expr.filter) {
if ((match = Expr.leftMatch[type].exec(expr)) != null && match[2]) {
var found, item, filter = Expr.filter[type], left = match[1];
anyFound = false;
match.splice(1, 1);
// leftMatch的意义在于判断表达式前面的字符是否为转义符
if (left.substr(left.length - 1) === "\\") {
continue;
}
// 这个条件看起来不可能成立 []!==[]
if (curLoop === result) {
result = [];
}
// 预过滤
if (Expr.preFilter[type]) {
match = Expr.preFilter[type](match, curLoop, inplace, result, not, isXMLFilter);
if (!match) {
anyFound = found = true;
} else if (match === true) {
continue;
}
}
if (match) {
for (var i = 0; (item = curLoop[i]) != null; i++) {
// 这里的判读多余
if (item) {
// 过滤
found = filter(item, match, i, curLoop);
// 使用异或运算获取补集,比普通的逻辑书写优雅多了 Nice
var pass = not ^ !! found;
if (inplace && found != null) {
if (pass) {
anyFound = true;
} else {
curLoop[i] = false;
}
} else if (pass) {
result.push(item);
anyFound = true;
}
}
}
}
if (found !== undefined) {
if (!inplace) {
curLoop = result;
}
expr = expr.replace(Expr.match[type], "");
if (!anyFound) {
return [];
}
break;
}
}
}
// Improper expression
if (expr === old) {
if (anyFound == null) {
Sizzle.error(expr);
} else {
break;
}
}
old = expr;
}
return curLoop;
};
####预过滤 预过滤主要是用于修正表达式的参数以便于接下来的过滤操作。但有个特例,ClASS选择器的过滤直接在预过滤过程中完成,不需要再执行后续的过滤。这里截取部分源码说明。
//预过滤
var Expr.preFilter = {
CLASS: function (match, curLoop, inplace, result, not, isXML) {
match = " " + match[1].replace(/\\/g, "") + " ";
if (isXML) {
return match;
}
for (var i = 0, elem; (elem = curLoop[i]) != null; i++) {
if (elem) {
if (not ^ (elem.className && (" " + elem.className + " ").replace(/[\t\n]/g, " ").indexOf(match) >= 0)) {
if (!inplace) {
result.push(elem);
}
} else if (inplace) {
curLoop[i] = false;
}
}
}
// 由于在上面的步骤中已经执行了过滤操作,故这里一律返回false,不需要执行后面的后面的过滤操作。
return false;
},
// 部分其他选择器只是修正表达式参数
ID: function (match) {
return match[1].replace(/\\/g, "");
},
//...
}
####过滤 将经过修正后的表达式交给Expr.filter执行最后一层过滤。这个过程中是根据Element节点自身的属性(如id,class, attribute, pseudo等)来过滤。所以涉及情况非常繁多,所以函数间的调用也会稍微复杂,比如伪类的过滤(Expr.filter.PSEUDO)调用了Expr.filters来执行过滤,位置选择器的过滤下(Expr.filter.POS)调用了Expr.setFilters来执行过滤。如果感觉有点头大,请参照前面提到的Sizzle函数结构图。
var Expr.filter = {
ID: function (elem, match) {
return elem.nodeType === 1 && elem.getAttribute("id") === match;
},
ATTR: function (elem, match) {
// 可结合前面定义的正则看
// ATTR: /\[\s*((?:[\w\u00c0-\uFFFF\-]|\\.)+)\s*(?:(\S?=)\s*(['"]*)(.*?)\3|)\s*\]/,
var name = match[1],
result = Expr.attrHandle[name] ? Expr.attrHandle[name](elem) : elem[name] != null ? elem[name] : elem.getAttribute(name),
value = result + "",
type = match[2],
check = match[4];
// 把源码格式化了下,看起来简单多了 t_t
// 判断Element节点的属性是否和选择器中的属性匹配
return result == null ? type === "!=" :
type === "=" ? value === check :
type === "*=" ? value.indexOf(check) >= 0 :
type === "~=" ? (" " + value + " ").indexOf(check) >= 0 :
!check ? value && result !== false :
type === "!=" ? value !== check :
type === "^=" ? value.indexOf(check) === 0 :
type === "$=" ? value.substr(value.length - check.length) === check :
type === "|=" ? value === check || value.substr(0, check.length + 1) === check + "-" :
false;
},
// ...
}
###终极筛选
经过一系列查询和过滤之后,Sizzle结合映射集在结果集中筛选符合条件的结果。
if (toString.call(checkSet) === "[object Array]") {
// 这里前面已经解释过了
if (!prune) {
results.push.apply(results, checkSet);
} else if (context && context.nodeType === 1) {
for (i = 0; checkSet[i] != null; i++) {
// 你可能会明白了前面为什么经常把布尔值存入到映射集中了,映射集才不是最终结果呢
if (checkSet[i] && (checkSet[i] === true || checkSet[i].nodeType === 1 && Sizzle.contains(context, checkSet[i]))) {
results.push(set[i]);
}
}
} else {
for (i = 0; checkSet[i] != null; i++) {
if (checkSet[i] && checkSet[i].nodeType === 1) {
results.push(set[i]);
}
}
}
} else {
makeArray(checkSet, results);
}
if (extra) {
Sizzle(extra, origContext, results, seed);
Sizzle.uniqueSort(results);
}
就这样,第一个群组选择器搞定了,如果还有其他群组选择器(extra),则递归调用sizzle查询extra,最后对结果进行合并、去重、排序。整体流程分析至此,大致流程图。
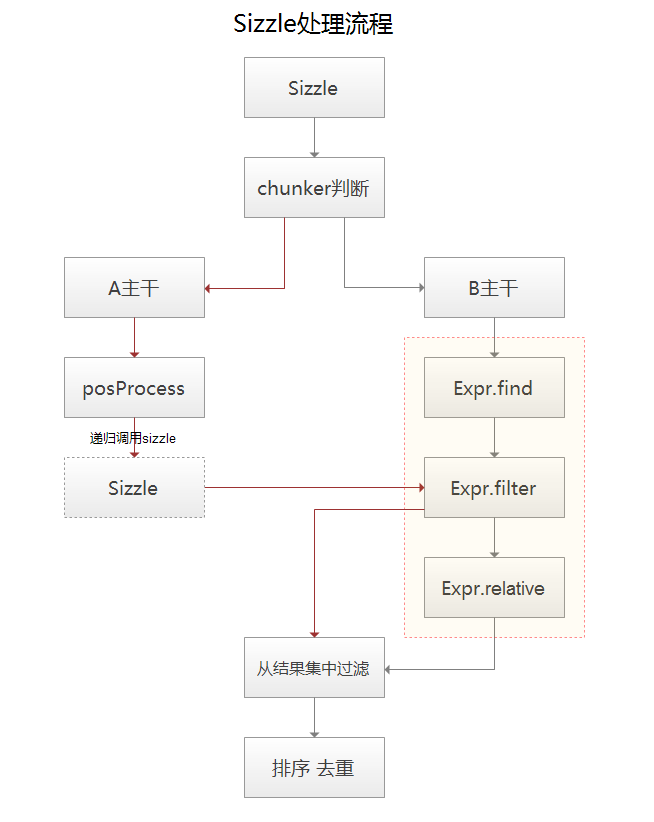
若有不当,还请斧正。