Sizzle浅析-2
- Time: 26 November 2012
- Categories:
- Frontend 27
- Tags:
- Sizzle 7
- jQuery 7
- Javascript 21
Sizzle首先通过chunker正则将冗长的表达式提取整理为数组,为后续查询、过滤做好准备。
###chunker正则提取表达式 chunker正则定义如下:
var chunker = /((?:\((?:\([^()]+\)|[^()]+)+\)|\[(?:\[[^\[\]]*\]|['"][^'"]*['"]|[^\[\]'"]+)+\]|\\.|[^ >+~,(\[\\]+)+|[>+~])(\s*,\s*)?((?:.|\r|\n)*)/g ;
一段看起来非常复杂的正则表达式,我们通过正则处理工具 处理后,思路变得清晰起来,由于正则较长,后面描述皆用图中标注的$n来指代对应的正则,如图:
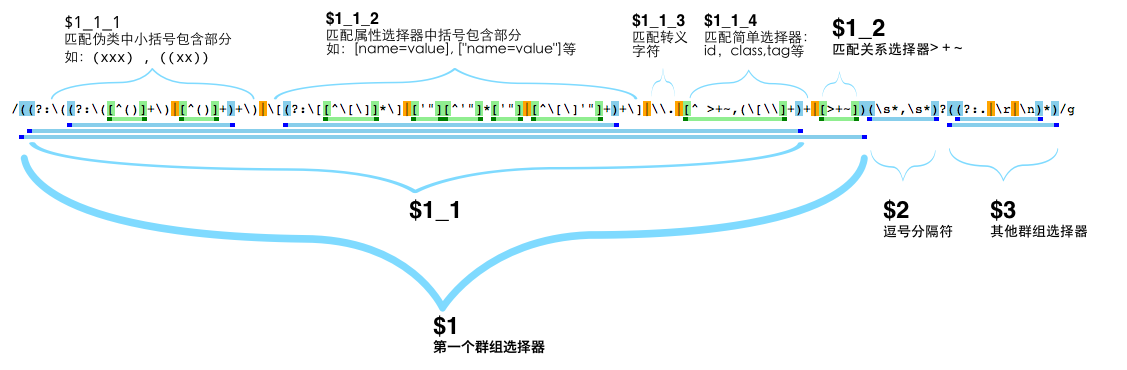
chunker正则将字符串从左往右分为三部分:
- $1:
((?:...)+|[>+~])匹配第一个群组表达式, - $2:
(\s*,\s*)?匹配群组选择器分隔符(”,”), - $3:
((?:.|\r|\n)*)匹配剩余部分。
第一个表达式$1又分为两部分,记作$1_1, $1_2([>+~])。这样便可将选择器以及他们之间的位置关系剥离出来,如:div#id+span 被循环匹配得到数组['div#id', '+', 'span']。
$1_1又分为四部分:$1_1_1, $1_1_2, $1_1_3, $1_1_4。这样分割后,对各个小片段分析就方便多了。
- $1_1_1: 匹配伪类中小括号部分,如,(attr)和((attr))
- $1_1_2: 匹配属性选择器的中括号部分,这部分表达式中又细分了三类情况:
[[xxx]](或[[name=value]])["xxx"](或["name=value"])[xxx](或[name=value])
- $1_1_3: 匹配转义字符,如\u9706
- $1_1_4: 匹配简单选择器,如id选择器(#id), class选择器(.class), 标签选择器等
chunker看起来很复杂,细细拆开分析下还是不难。它每次只匹配一部分表达式,对剩余部分循环匹配从而获取完整的表达式数组。
测试:
var chunker = /((?:\((?:\([^()]+\)|[^()]+)+\)|\[(?:\[[^\[\]]*\]|['"][^'"]*['"]|[^\[\]'"]+)+\]|\\.|[^ >+~,(\[\\]+)+|[>+~])(\s*,\s*)?((?:.|\r|\n)*)/g ;
// 测试表达式
var selector = 'div#wrap .sliding li a.on';
// 循环捕获表达式
var m, extra,
parts = [],
soFar = selector;
do {
chunker.exec("");
m = chunker.exec(soFar);
if (m) {
soFar = m[3];
parts.push(m[1]);
if (m[2]) {
extra = m[3];
break;
}
}
} while (m);
//output: ["div#wrap", ".sliding", "li", "a.on"]
console.log(parts);
在代码中循环使用chunker分割选择器表达式,将所得结果存入到parts数组,如果有群组选择器“,”,只分割至第一个逗号前的选择器表达式,将剩余部分暂存到extra中,在Sizzle底部会再次对extra变量进行递归操作。如:'div#wrap > li a.on, div.tab_bd li a' ,会得到parts为['div#wrap', '>', 'a.on'],逗号后面的表达式会暂存入extra。
上面内容主要分析了chunker正则是如何匹配、分组表达式字符串的,在下一篇中将继续分析sizzle的处理流程。